• Seven papers submitted by OPPO were selected for presentation at the 2022 Computer Vision and Pattern Recognition Conference, breaking a new record for the company. The selected papers cover OPPO’s various R&D breakthroughs in a range of artificial intelligence disciplines
• OPPO received a total of eight prizes in the CVPR challenges, including three first-place, one second place, and four third place prizes
|
The annual Computer Vision and Pattern Recognition Conference (CVPR) came to an end in New Orleans, with globallyleadingtechnologycompany OPPO successfully having seven of its submitted papers selected for the conference, putting it among the most successful technology companies at the event.OPPO also placed in eight of the widely watched competition events at the conference, taking home three first place, one second place, and four third place prizes.
“In 2012, deep neural networks designed for image recognition rejuvenated the research and application of artificial intelligence. Ever since, AI technology has seen a decade of rapid development.”said GuoYandong, Chief Scientist in Intelligent Perception at OPPO.
“OPPO continues to promote artificial intelligence to accomplish complex perceptual and cognitive behaviors.We empower AI with higher cognitive abilities to understand and create beautyand develop embodied AI with autonomous behavior. I’m delighted to see that seven of our papers have been selected for this year’s conference. Building on this success, we will continue to explore both fundamental AI and cutting-edge AI technology, as well as the commercial applications that will enable us to bring the benefits of AI to more people.”
The Seven papers acceptedby CVPR 2022 showcase OPPO‘sprogressin creating humanizing AI
Seven papers submitted by OPPO for CVPR 2022 were selected for presentation at the conference. Their areas of research include multimodal information interaction, 3D human body reconstruction, personalized image aesthetics assessment, knowledge distillation, and others.
Cross-modular innovation is viewed as the way to 'humanizing' artificial intelligence. Text data frequently includes an elevated degree of over-simplification, while visual picture data contains a lot of specific contextual details.OPPO researchers proposed a new CRIS framework based on the CLIP model to enable AI to get a more fine-grained understanding ofthe text and image modal data.
The biggest difference between human and artificial intelligence today lies in multimodality. Humans can undoubtedly figure out data in both words and pictures and draw relationship between the two sorts of data. The novel method proposed by OPPO improves multimodal intelligence, which could potentially lead to artificial intelligence being able to truly understand and interpret the world through multiple forms of information such as language, hearing, vision, and others, making the robot and digital assistants of sci-fi movies become a reality.
|
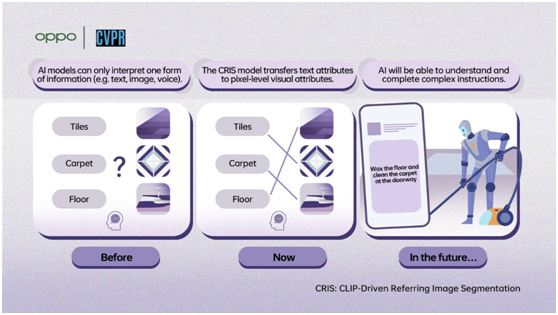
CRIS: CLIP-Driven Referring Image Segmentation
|
3D human body remaking is one more region in which the OPPO Research Institute has made significant progress. At CVPR, OPPO demonstrated a process for automatically generating digital avatars of humans with clothing that behaves more naturally. By analyzing RGB video of humans captured with a camera, the OPPO model can accurately generate 3D, 1:1 dynamic models that include small details like logos or fabric textures. Creating accurate 3D models of clothes has remained one of the biggest challenges. The new model effectively reduces the requirements needed to perform 3D human body reconstruction, providing technical foundations that can be applied to areas such as virtual dressing rooms for online shopping, AI fitness instruction, and the creation of lifelike avatars in VR/AR worlds.
|
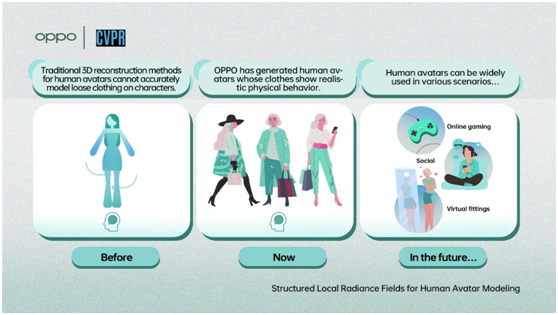
Structured Local Radiance Fields for Human Avatar Modeling |
AI image recognition has now reached a stage where it can accurately identify a wide range of objects within an image. The ability of AI to evaluate images in terms of their perceived aesthetic quality is often strongly related to the big data used in training the AI model.
In collaboration with Leida Li, a professor from Xidian University proposed Personalized Image Aesthetics Assessment (PIAA) model. The model is the first to optimize AI aesthetics assessment by combining users' subjective preferences with more generalized aesthetic values.In the future, the model will be used to create personalized experiences for users, not just limited to the curation of photo albums, but also provide recommendations on how to shoot the best photo and which content a user might prefer.
|
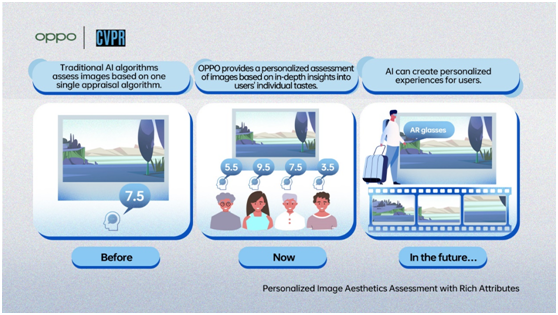
Personalized Image Aesthetics Assessment with Rich Attributes |
OPPO has also chosen to make the PIAA model evaluation data set the open source for developers, with a number of research institutions and universities already expressing an interest in using the data to further their own efforts in personalized AI aesthetic assessment.
Further to this, OPPO also proposed a multi-view 3D semantic plane reconstruction solution capable of accurately analyzing surfaces within a 3D environment. Developed in partnership with Tsinghua University, the INS-Conv (INcremental Sparse Convolution) can achieve faster and more accurate online 3D semantic and instance segmentation. This can effectively reduce the computing power needed to perform environment recognition, which will enable such technology to be more easily adopted in applications such as automated driving and VR.
OPPO makes AI ‘lightweight’ with second place win in the NAS Challenge
CVPR 2022 also saw a number of technical challenges take place, with OPPO placing third and above in eight challenges. These include the neural architecture search (NAS) challenge, SoccerNet, SoccerNet Replay Grounding,ActivityNet temporal localization, the 4th Large-scale Video Object Segmentation Challenge.
From mobile photography to automated driving, deep learning models are being applied in an increasingly large pool of industries. However, deep learning relies heavily on big data and calculation power and consumes a lot of cost, both of which present challenges to its commercial implementation. Neural architecture search (NAS) techniques can automatically discover and implement optimal neural network architectures. In the NAS competition, OPPO researchers trained a supernetwork of 45,000 sub neural networks to inherit the parameters of the supernetworkby optimizing the Model.
Using the NAS technique, researchers only need to train a large supernetwork and create a predictor to let the subnetworks learn by inheriting the supernetwork parameters. This provides an efficientand low-cost approach to obtaining a deep learning model that outperforms those manually designed by expert network architects. This will ultimately bring previously unthinkable levels of AI technology to mobile devices in the near future.
During CPVR 2022, OPPO also participated in seminar presentations and three high-level workshops. At the SLAM seminar, OPPO researcher Deng Fan shared how real-time vSLAM could be run on smartphones and AR/VR devices. In AICITY Workshop, Li Wei proposed a multi-view based motion localization system to identify abnormal behavior of drivers while driving.
OPPO is bringing the benefits of AI to more people, sooner
This is the third year that OPPO has participated at CVPR. OPPO’s rising success at CVPR during these three years owes much to its continued investment in AI technology. At the beginning of 2020, the Institute of Intelligent Perception and Interaction was established under the OPPO Research Institute to further deepen OPPO’s exploration of cutting-edge AI technologies. Today, OPPO has more than 2,650 global patent applications in the field of AI.
Guided by its brand proposition, ‘Inspiration Ahead’, OPPO is also working with partners across the industry to take AI technology from the laboratory into daily life. OPPO’s AI technology has also been used to develop products and features such as the real-time spatial ARgenerator CybeReal, OPPO Air Glass, Omoji, and more. Through these technologies, OPPO is aiming to create more lifelike digital worlds that combine virtual and reality to create all-new experiences for users.
|